





Le più comuni problematiche con gli Starburst e come risolverle
Gli Starburst sono componenti fondamentali in molti sistemi di data analytics e business intelligence grazie alla loro elevata velocità e scalabilità. Tuttavia, come qualsiasi tecnologia avanzata, possono presentare problematiche che, se non affrontate correttamente, compromettendo le prestazioni complessive. In questo articolo, esploreremo le principali cause di malfunzionamenti, come riconoscerle e come intervenire efficacemente per garantire un funzionamento ottimale.
Indice
Cause tecniche frequenti che compromettono la performance degli Starburst
Malfunzionamenti hardware e come identificarli
Gli errori hardware rappresentano una delle cause più comuni di degrado nelle prestazioni di Starburst. Componenti come CPU, RAM o SSD difettosi o sovraccarichi possono provocare rallentamenti improvvisi o blocchi del sistema. Per identificarli, è fondamentale monitorare in tempo reale le metriche hardware utilizzando strumenti come Nagios, Zabbix o Soluzioni di monitoraggio integrate. Inoltre, la presenza di errori di I/O o crash frequenti del sistema operativo può indicare problemi hardware sottostanti.
Ad esempio, un aggiornamento firmware non compatibile o obsolete può portare a malfunzionamenti hardware indicandolo attraverso messaggi di errore specifici (ad esempio, errori di SCRATCH o di BIOS).
Problemi di configurazione software e soluzioni pratiche
Una configurazione software errata può limitare la capacità di Starburst di sfruttare al massimo le risorse disponibili. Questo include parametri di configurazione come allocazione di memoria, impostazioni di rete e parametri di sistema. Per risolvere tali problemi, è consigliabile seguire le best practice di configurazione proposte dal vendor e utilizzare strumenti di audit per verificare che le impostazioni siano ottimali. La corretta configurazione dei lock della memoria, i limiti di CPU e le scelte di clusterizzazione sono fondamentali.
Ad esempio, una configurazione di memoria sottodimensionata può portare a crash frequenti o a rallentamenti. È utile quindi impostare alert che avvisino quando le risorse si avvicinano ai limiti critici, e in alcuni casi può essere utile consultare specialisti o servizi come servizio moro spin casino per ottimizzare le performance.
Impatto di aggiornamenti e patch sulla stabilità del sistema
Gli aggiornamenti sono essenziali per la sicurezza e le funzionalità, ma possono anche introdurre instabilità se non testati correttamente. È importante instaurare un processo di staging dove ogni patch viene verificata in ambienti di test prima dell’implementazione in produzione. Analizzare i registri di aggiornamento e condividere i feedback con i fornitori permette di individuare aggiornamenti problematici.
Un esempio concreto riguarda il rilascio di una nuova patch che, pur risolvendo vulnerabilità di sicurezza, crea conflitti con componenti legacy, causando interruzioni di servizio. La gestione preventiva e il test continuo costituiscono quindi strategie cruciali.
Come riconoscere segnali di inefficienza operativa negli Starburst
Indicatori di rallentamenti o blocchi improvvisi
Rallentamenti o blocchi improvvisi sono spesso il primo campanello di allarme. Questi possono manifestarsi attraverso timeout nelle query, errori di timeout di rete, o risposte lente alle richieste degli utenti.
Le cause spesso sono riconducibili a risorse intensive o a processi concorrenti che saturano la capacità del sistema.
Per esempio, una query complessa che lavora su enormi dataset può causare congestione. La soluzione è monitorare l’uso della CPU e della memoria durante tali operazioni e ottimizzare le query o l’infrastruttura sottostante.
Analisi delle metriche di utilizzo e performance
La raccolta e l’analisi delle metriche di sistema aiutano a identificare pattern di inefficienza. Metriche chiave includono CPU, RAM, I/O disk, connessioni di rete, e tempi di risposta delle query.
Tabella esemplificativa:
| Metriсa | Valore di riferimento | Segnale di problema |
|---|---|---|
| Uso CPU | Sotto 70% | Alto utilizzo prolungato può indicare sovraccarico |
| Utilizzo RAM | Sotto il 80% | Memory swap frequente indica sovraccarico |
| Tempo di risposta query | Inferiore a 2 secondi | Risposte superiori ai 5 secondi sono indicativo di problemi |
Identificare immediatamente variazioni di questi parametri permette di intervenire tempestivamente.
Segnali di degrado nelle connessioni di rete
Le connessioni di rete lente o instabili possono causare perdita di pacchetti, ritardi e timeout. La presenza di alti tassi di retransmissioni o di errori di CRC nei log di rete costituisce un campanello d’allarme.
Per esempio, in ambienti cloud ibridi, l’elevato traffico di rete o configurazioni di firewall restrittive possono influire sulle performance. La soluzione risiede nell’ottimizzazione della configurazione di rete, nell’aumento della banda disponibile, o nell’uso di connessioni dedicate.
Risposte pratiche alle problematiche di compatibilità con altri sistemi
Incompatibilità tra versioni di software e hardware
Spesso, le incompatibilità tra versioni di software e hardware portano a crash o comportamenti non previsti. Prima di aggiornare, è fondamentale consultare le release notes e verificare la compatibilità con l’hardware esistente.
Ad esempio, l’aggiornamento di Starburst a una versione più recente potrebbe non essere compatibile con processori obsoleti o sistemi operativi meno recenti. La strategia migliore consiste nel testare ogni nuovo rilascio in ambienti di staging prima di distribuirlo in produzione, riducendo così i rischi di incompatibilità.
Gestione di conflitti con strumenti di terze parti
I conflitti tra Starburst e altri strumenti di terze parti, come strumenti di orchestrazione, scheduler o database, sono frequenti. La risoluzione richiede una revisione approfondita delle configurazioni, degli standard di compatibilità e delle versioni.
Una pratica efficace è mantenere un catalogo aggiornato di tutte le componenti integrate e implementare un processo di testing di integrazione continuo per individuare tempestivamente i conflitti.
Strategie di aggiornamento per minimizzare i rischi
Per minimizzare i rischi di incompatibilità durante gli aggiornamenti si consiglia di:
- Effettuare backup completi prima di ogni aggiornamento
- Utilizzare ambienti di testing per verificare le nuove versioni
- Implementare aggiornamenti graduali su parti controllate del sistema
- Monitorare attentamente l’efficacia post-aggiornamento
Soluzioni efficaci per problemi di sicurezza e vulnerabilità
Identificazione delle falle di sicurezza più comuni
Le vulnerabilità più diffuse in ambienti che usano Starburst riguardano attacchi di tipo SQL injection, gestione impropria delle credenziali, e lacune di configurazione di sicurezza nei componenti di rete. È fondamentale effettuare audit di sicurezza regolari e utilizzare strumenti di analisi delle vulnerabilità come Nessus o OpenVAS.
Inoltre, le vulnerabilità di sicurezza spesso emergono post vulnerabilità note, che vengono sfruttate con attacchi automatizzati. Restare aggiornati sulle patch di sicurezza è quindi di vitale importanza.
Implementazione di patch di sicurezza e best practice
Un approccio proattivo include l’applicazione tempestiva delle patch, la configurazione di firewall restrittivi, e l’implementazione di autenticazione multifattoriale. È essenziale anche limitare i privilegi degli utenti alle funzioni strettamente necessarie, riducendo così le superfici di attacco.
Per esempio, isolare i nodi di database in subnet dedicate e utilizzare VPN sicure può essere determinante per la sicurezza dei dati.
Monitoraggio continuo delle potenziali minacce
Per una sicurezza efficace, occorre adottare sistemi di monitoraggio continuo come SIEM (Security Information and Event Management) che analizzano i log in tempo reale e inviano alert immediati in caso di comportamenti anomali. La correlazione tra eventi di rete, accessi e payload permette di identificare minacce emergenti prima che possano causare danni significativi.
In conclusione, la gestione delle problematiche di Starburst richiede un approccio sistemico, combinando monitoraggio proattivo, aggiornamenti tempestivi e attenzione alle pratiche di sicurezza. Solo così si può garantire che il sistema funzioni al massimo delle sue potenzialità, proteggendo i dati e ottimizzando le performance.
Chia sẻ bài viết





Tin sản phẩm

PHƯỚC BÌNH LAKEVIEW – SIÊU SẢN PHẨM KHU ĐÔ THỊ NAM SÂN BAY

NHỮNG TIỆN ÍCH HẤP DẪN DẪN TỪ SẢN PHẨM GOLDEN CENTER

GOLDEN CENTER – VỊ TRÍ TRUNG TÂM KẾT NỐI GIAO THÔNG HOÀN HẢO
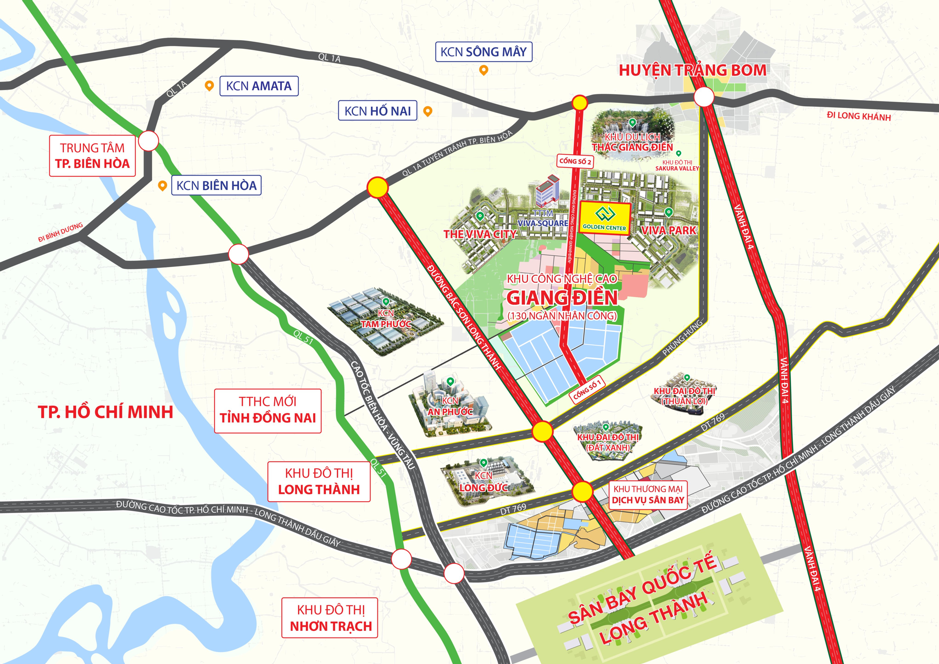
GOLDEN CENTER – SỨC HÚT CỦA VỊ TRÍ TRUNG TÂM
KHU DÂN CƯ AN NGÃI HƯỞNG LỢI TỪ QUY HOẠCH CỬA NGÕ BIỂN BÀ RỊA – VŨNG TÀU
Tin thị trường

BÌNH THUẬN SẴN SÀNG CHO LỄ KHỞI CÔNG CAO TỐC VĨNH HẢO – PHAN THIẾT – DẦU GIÂY NGÀY 30/9

CAO TỐC, SÂN BAY, BẾN CẢNG: AI KHÔNG LÀM THÌ ĐỨNG SANG MỘT BÊN !

(CAFEF.VN) – HAI YẾU TỐ “VÀNG” SẼ TẠO SỨC BẬT CHO THỊ TRƯỜNG BĐS NGAY KHI DỊCH BỆNH KẾT THÚC

(CAFEF.VN) – TRONG KHÓ KHĂN THÁCH THỨC, NHIỀU NHÀ ĐẦU TƯ BĐS COI ĐÂY LÀ CƠ HỘI VÀ LẠC QUAN VÀO THỊ TRƯỜNG TRONG DÀI HẠN

(CAFELAND.VN) – ĐỒNG NAI: HƠN 3.100 TỈ ĐỒNG XÂY TUYẾN ĐƯỜNG TRUNG TÂM TP. BIÊN HÒA
Hoạt động