





Confronto tra “le bandit” e algoritmi di reinforcement learning per decisioni rapide
Principi fondamentali e differenze tra metodi di apprendimento automatico
Come funzionano le tecniche di “le bandit” e cosa le distingue dai modelli di reinforcement learning
Le tecniche di “multinomial bandit” sono algoritmi di ottimizzazione semplice che mirano a massimizzare il reward attraverso decisioni sequenziali, scegliendo tra diverse opzioni disponibili. Questo metodo si basa sul principio di esplorazione e sfruttamento: esplorare nuove possibilità per scoprire potenziali benefici, mantenendo attivo anche l’utilizzo delle soluzioni più note. Le “bandit” sono caratterizzate da una struttura statica, dove le azioni sono limitate e i feedback immediati, ottimizzati per scenari con risorse limitate o tempi ristretti.
Il reinforcement learning (RL), invece, implica un agente che interagisce con un ambiente complesso, apprendendo una strategia ottimale attraverso trial-and-error. Il RL utilizza reti neurali, funzioni di valore e policy per apprendere comportamenti che massimizzano ricompense a lungo termine, spesso in ambienti dinamici e con stati multipli. La differenza sostanziale risiede nella complessità delle decisioni: le “bandit” sono adatte a problemi con opzioni fisse e feedback immediato, mentre il RL si occupa di sequenze di decisioni più articolate con feedback a lungo termine. Per approfondire le applicazioni di queste tecniche nel settore dei giochi, puoi consultare https://joy-casino.co.it.
Vantaggi e limiti di approcci basati sulle “bandit” rispetto agli algoritmi di reinforcement learning
I principali vantaggi delle “bandit” sono semplicità di implementazione, velocità di esecuzione e minore richiesta di dati e risorse computazionali. Sono ideali per decisioni rapide come campagne pubblicitarie online o offerte di marketing, dove è fondamentale rispondere subito ai cambiamenti del mercato.
Al contrario, gli algoritmi di reinforcement learning offrono risultati più sofisticati in scenari complessi, dove bisogna considerare le conseguenze a lungo termine delle decisioni. Tuttavia, hanno limiti di convergenza più lunghi, maggiore complessità di deploying e richiedono grandi quantità di dati per addestramento, spesso con risorse elevate.
Implicazioni pratiche nella scelta tra le due soluzioni in contesti real-time
In ambienti che richiedono decisioni immediato, come la gestione di traffico web o l’allocazione di risorse in tempo reale, le “bandit” rappresentano la soluzione più pragmatica. La loro capacità di adattarsi velocemente con minime risorse è un vantaggio competitivo
Per decisioni più ponderate, che coinvolgono numerose variabili e benefici a lungo termine, l’uso di algoritmi di reinforcement learning può essere preferibile, anche se implica una fase di training più lunga e complessa.
Applicazioni pratiche in settori ad alta velocità decisionale
Esempi di utilizzo delle “bandit” nelle campagne di marketing digitale
Nel marketing digitale, le “bandit” vengono utilizzate per ottimizzare le campagne pubblicitarie in tempo reale. Ad esempio, piattaforme come Google Ads impiegano algoritmi bandit per decidere quale annuncio mostrare, in base alle performance immediate, adattando continuamente le strategie per massimizzare il click-through rate (CTR). Secondo uno studio di Adobe (2022), le aziende che adottano approcci bandit hanno aumentato del 20% il ritorno sull’investimento pubblicitario rispetto ai metodi tradizionali.
Implementazioni di reinforcement learning per ottimizzare decisioni in finanza e trading
Nel settore finanziario, gli algoritmi di reinforcement learning vengono impiegati per gestire portafogli, prevedere tendenze di mercato e automatizzare le operazioni di trading. Questi sistemi analizzano sequenze di dati storici, apprendendo strategie che si adattano ai cambiamenti di mercato, spesso con risultati superiori rispetto ai metodi tradizionali. Per esempio, in un case study di JP Morgan (2023), l’uso di RL ha consentito di aumentare i profitti di trading automatico del 15% rispetto ai sistemi basati su regole fisse.
Settori emergenti: gaming e robotica, dove scegliere tra le due tecniche
Nei giochi online e nella robotica, la decisione rapida è cruciale. I sistemi di gioco real-time si affidano spesso alle “bandit” per adattare le strategie in modo efficiente, mentre robot autonomi in ambienti dinamici come i magazzini robotizzati utilizzano reinforcement learning per migliorare le proprie capacità di navigazione e interazione nel tempo.
Performance e rapidità di adattamento in ambienti dinamici
Analisi comparativa di tempi di convergenza e capacità di adattamento
| Metodo | Tempo di convergenza | Capacità di adattamento rapido |
|---|---|---|
| Le bandit | Molto breve, spesso pochi episodi | Elevata, ottimo per situazioni che cambiano frequentemente |
| Reinforcement learning | Più lungo, può richiedere migliaia di iterazioni | Variabile, può richiedere riaddestramenti significativi in ambienti instabili |
Come le “bandit” garantiscono risposte rapide con risorse limitate
Le “bandit” sono progettate per operare con scarse risorse computazionali e in tempo molto breve. Ad esempio, in A/B testing di pagine web, una strategia bandit può aggiornare continuamente le versioni più performanti, offrendo risposte ottimali in pochi minuti, ottimizzando l’esperienza utente sul momento.
Vulnerabilità degli algoritmi di reinforcement learning in situazioni di decisione istantanea
Gli algoritmi di reinforcement learning, sebbene potenti, sono spesso troppo lenti nel reagire a cambiamenti repentini, perché richiedono molte iterazioni per convergere a una strategia ottimale. Questo li rende meno adatti a situazioni in cui ogni secondo conta, come il trading ad alta frequenza o la gestione di emergenze in robot autonomi.
Impatto sulla produttività e sui risultati aziendali
Studi recenti che evidenziano miglioramenti concreti con l’uso delle “bandit”
Secondo un rapporto di McKinsey (2023), le aziende che hanno adottato strategie basate sulle “bandit” hanno registrato un incremento medio del 25% nelle conversioni marketing e una riduzione dei costi pubblicitari del 15%. La capacità di adattarsi velocemente alle preferenze dei clienti si traduce in risultati immediati e misurabili.
Come gli algoritmi di reinforcement learning contribuiscono a processi decisionali complessi
Nel settore industriale, il reinforcement learning viene impiegato per ottimizzare processi complessi come la logistica e la produzione, dove le decisioni hanno molte variabili e effetti a lungo termine. Un esempio è l’automazione di catene di montaggio intelligenti, che imparano a ridurre i tempi di produzione e migliorare la qualità nel tempo.
Analisi di casi aziendali di successo e insuccesso
- Successo: Alibaba ha adottato algoritmi di bandit per personalizzare offerte e raccomandazioni, aumentando le conversioni del 30% in un anno.
- Insuccesso: alcune startup hanno tentato di implementare reinforcement learning senza dati sufficienti, portando a decisioni sub-ottimali e investimenti falliti.
Considerazioni sui costi e la complessità implementativa
Risorse richieste e difficoltà di deployment delle “bandit”
Le “bandit” sono relativamente semplici da implementare, richiedendo poche risorse e un’architettura leggera. Questo le rende adatte a progetti con budget limitati o a team con competenze più semplici. Tuttavia, la scelta deve considerare la complessità del problema: in scenari più articolati, le “bandit” possono risultare troppo semplicistiche.
Costi di sviluppo e manutenzione degli algoritmi di reinforcement learning
Gli algoritmi di reinforcement learning richiedono infrastrutture hardware avanzate, team specializzati e tempi di sviluppo più lunghi. La manutenzione è complessa, poiché i modelli devono essere continuamente aggiornati e riaddestrati, sostenendo costi elevati e richiedendo expertise tecnico elevata.
Fattori di scelta economica tra le due tecniche in progetti aziendali
La decisione tra “bandit” e reinforcement learning deve considerare il rapporto tra costo, tempo di implementazione e beneficio atteso. In scenari di decisioni rapide e limitate, le “bandit” sono più economiche e pratiche. Al contrario, investimenti più consistenti in RL sono giustificati in progetti complessi e strategici a lungo termine.
Chia sẻ bài viết





Tin sản phẩm

PHƯỚC BÌNH LAKEVIEW – SIÊU SẢN PHẨM KHU ĐÔ THỊ NAM SÂN BAY

NHỮNG TIỆN ÍCH HẤP DẪN DẪN TỪ SẢN PHẨM GOLDEN CENTER

GOLDEN CENTER – VỊ TRÍ TRUNG TÂM KẾT NỐI GIAO THÔNG HOÀN HẢO
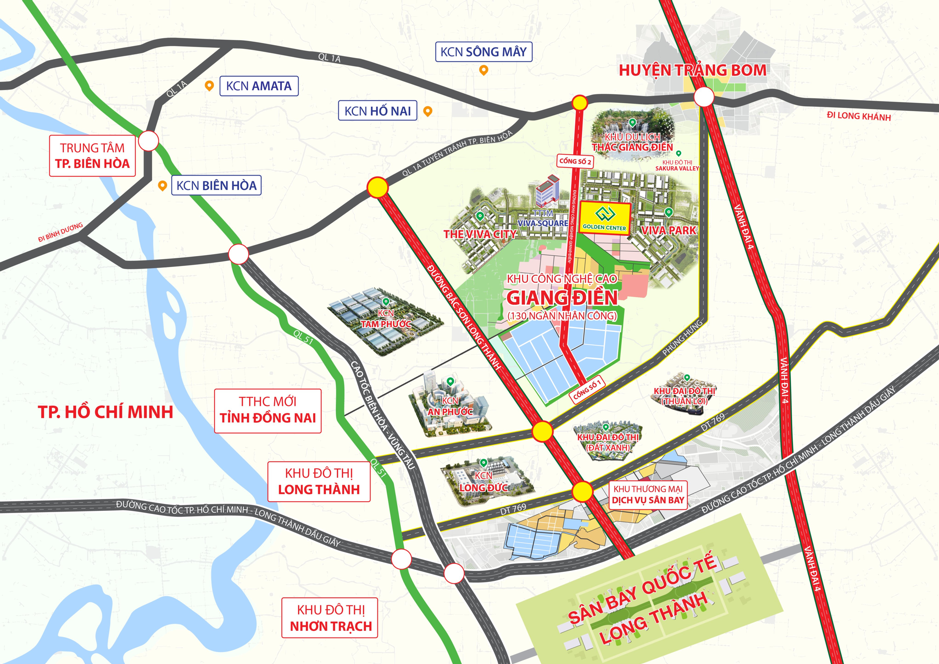
GOLDEN CENTER – SỨC HÚT CỦA VỊ TRÍ TRUNG TÂM
KHU DÂN CƯ AN NGÃI HƯỞNG LỢI TỪ QUY HOẠCH CỬA NGÕ BIỂN BÀ RỊA – VŨNG TÀU
Tin thị trường

BÌNH THUẬN SẴN SÀNG CHO LỄ KHỞI CÔNG CAO TỐC VĨNH HẢO – PHAN THIẾT – DẦU GIÂY NGÀY 30/9

CAO TỐC, SÂN BAY, BẾN CẢNG: AI KHÔNG LÀM THÌ ĐỨNG SANG MỘT BÊN !

(CAFEF.VN) – HAI YẾU TỐ “VÀNG” SẼ TẠO SỨC BẬT CHO THỊ TRƯỜNG BĐS NGAY KHI DỊCH BỆNH KẾT THÚC

(CAFEF.VN) – TRONG KHÓ KHĂN THÁCH THỨC, NHIỀU NHÀ ĐẦU TƯ BĐS COI ĐÂY LÀ CƠ HỘI VÀ LẠC QUAN VÀO THỊ TRƯỜNG TRONG DÀI HẠN

(CAFELAND.VN) – ĐỒNG NAI: HƠN 3.100 TỈ ĐỒNG XÂY TUYẾN ĐƯỜNG TRUNG TÂM TP. BIÊN HÒA
Hoạt động